Map 类型,是由若干个 key:value 这样的键值对映射组合在一起的数据结构。
它是哈希表的一个实现,这就要求它的每个映射里的key,都是唯一的,可以使用 == 和 != 来进行判等操作,换句话说就是key必须是可哈希的。
简单来说,可哈希就是一个不可变对象。在Go语言中,除了切片、字典、函数其他内建数据类型都是不可变对象。
字典由key和value组成,它们各自有各自的类型。
在声明字典时,必须指定好你的key和value是什么类型的,然后使用map 关键字来告诉Go这是一个字典。
// 默认赋值nil 不能初始化值。一般用于整体赋值
// var userinfo map[string]string
var userinfo map[string]string = map[string]string{"name":"augustrush", "age":"18"}
userinfo := map[string]string{"name": "August", "age": 18}
userinfo := make(map[string]int)
userinfo["name"] = 1
userinfo["age"] = 18
// userinfo := make(map[string]string, 10) // 简单来说初始化容量10的map
userinfo := make(map[string]string{"name": "August", "age": 18})
userinfo["job"] = "Python Developer"
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下:
delete(map, key)
userinfo := make(map[string]string{"name": "August", "age": 18})
delete[userinfo, "age"]
userinfo := make(map[string]string{"name": "August", "age": 18})
userinfo["job"] = "Go Developer"
userinfo := make(map[string]string{"name": "August", "age": 18})
// 查询单个值
fmt.Println(userinfo["job"])
// 查询map内所有键-值
for key, value := range userinfo {
fmt.Println(key, value)
}
// 查询map内所有键
for key := range userinfo {
fmt.Println(key)
}
// 查询map内所有值
for _, value := range userinfo {
fmt.Println(value)
}
Go语言中有个判断map中键是否存在的特殊写法,格式如下:
value, ok := map[key]
当key不存在,会返回value-type的零值 ,所以你不能通过返回的结果是否是零值来判断对应的 key 是否存在,因为 key 对应的 value 值可能恰好就是零值。
其实字典的下标读取可以返回两个值,使用第二个返回值都表示对应的 key 是否存在,若存在ok为true,若不存在,则ok为false
scoreMap := map[string]int{"august": 100, "grecia": 59}
value, ok := scoreMap["august"]
if ok {
fmt.Println("key存在,值为", value)
}else {
fmt.Println("key不存在, 值为", value)
}
userinfo := make(map[string]string{"name": "August", "age": "18"})
fmt.Println(len(userinfo))
// cap(userinfo) 不能通过cap来测量出map的容量
m1 := map[string][2]int {"august": [2]int {100,90}, "grecia": [2]int {59, 10}}
/*
输出结果:
map[august:[100 90] grecia:[59 10]]
*/
m2 := map[string][]string{
"河南省": []string{"郑州市", "许昌市", "开封市", "洛阳市"},
"湖北省": []string{"武汉市", "孝感市"},
}
fmt.Println(m2)
/*
输出结果:
map[河南省:[郑州市 许昌市 开封市 洛阳市] 湖北省:[武汉市 孝感市]]
*/
m3 := make(map[string]map[string][]string)
m3["中国"] = map[string][]string{
"河南省": []string{"郑州市", "许昌市", "开封市", "洛阳市"},
"湖北省": []string{"武汉市", "孝感市"},
}
fmt.Println(m3)
/*
输出结果:
map[中国:map[河南省:[郑州市 许昌市 开封市 洛阳市] 湖北省:[武汉市 孝感市]]]
*/
m4 := make(map[[2]int]string)
m4[[2]int{1, 2}] = "一个value"
fmt.Println(m4)
/*
输出结果:
map[[1 2]:一个value]
*/
Go中的map有自己的一套实现原理,其核心是由hmap和bmap两个结构体实现。
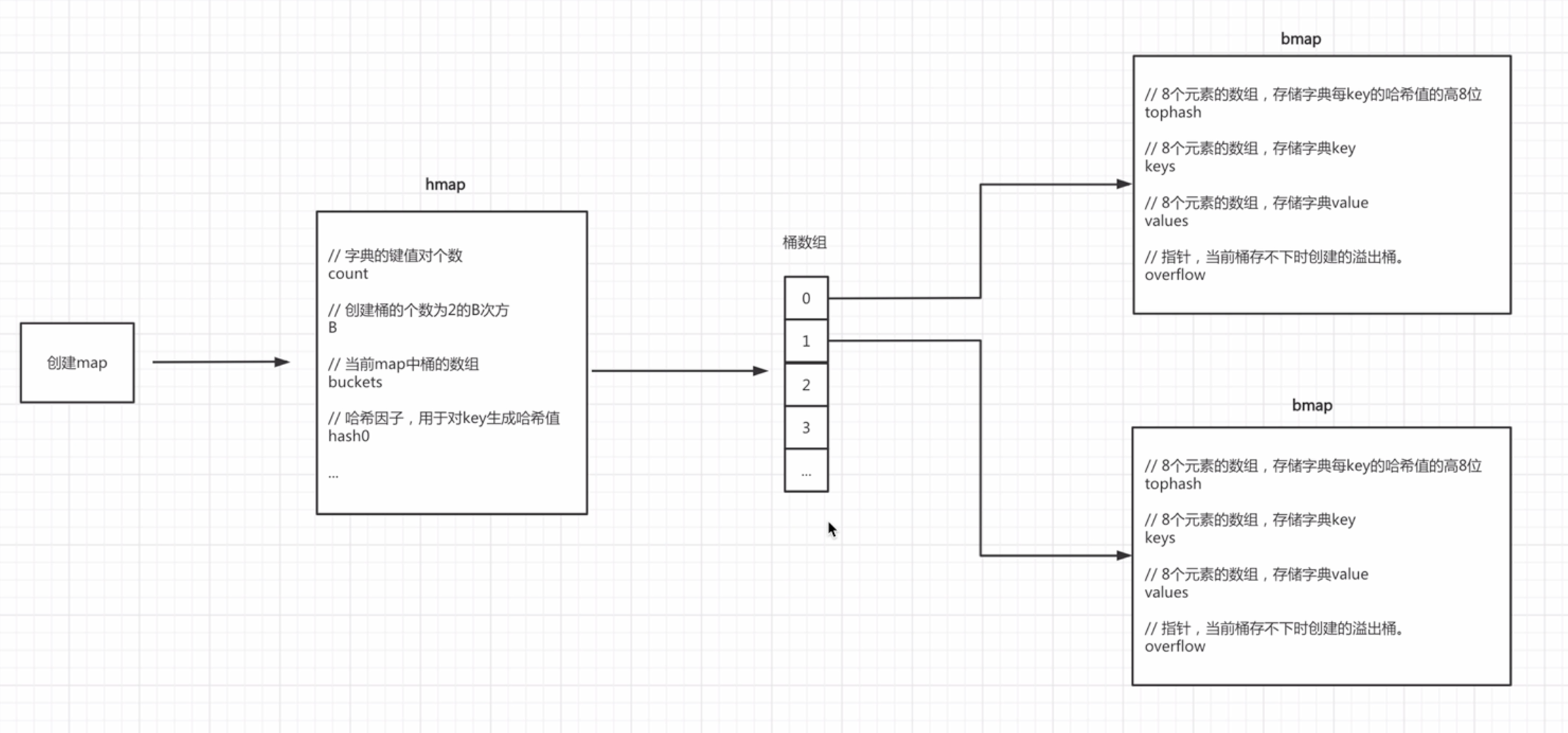
// 初始化一个可容纳10个元素的map
info := make(map[string]int, 10)
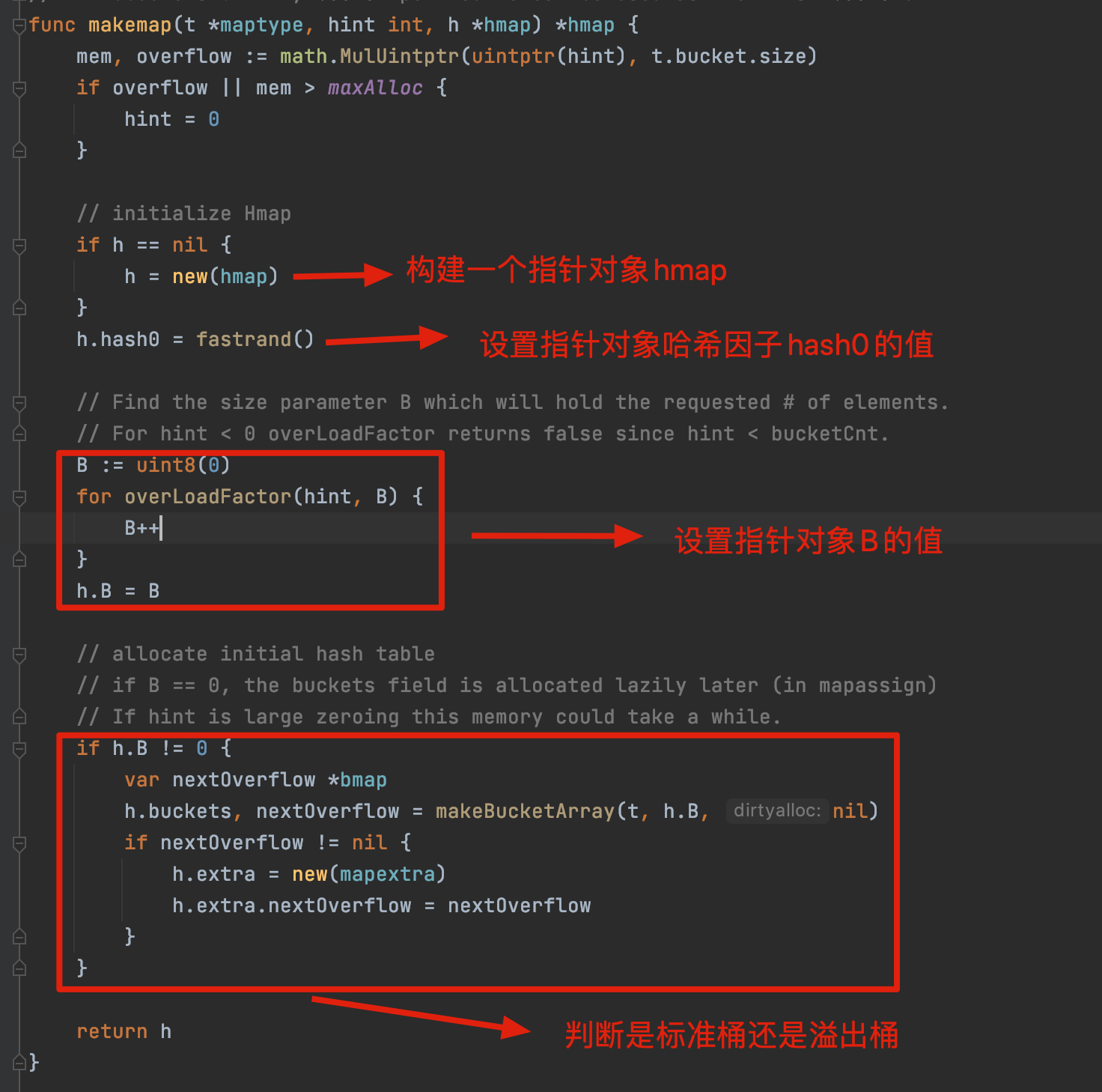
第一步: 创建一个hmap结构体对象
第二步: 生成一个哈希因子hash0并赋值到hmap对象中(用于后续为key创建哈希值)。
第三步: 根据hint=10,并根据算法规则来创建B,当前B应该为1。
hint B
0~8 0
9~13 1
14~26 2
...
第四步:根据B去创建桶(bmap对象)并存放在buckets数组中,当前bmap的数量应为2。
当B<4时,根据B创建桶的个数的规则为:2^B^(标准桶)
当B>=4时,根据B创建桶的个数的规则为:2^B^+2^B-4^(标准桶+溢出桶)
每个bmap中可以存储8个键值对,当不够存储时需要使用溢出桶,并将当前bmap中的overflow字段指向溢出桶的位置。
info["name"] = "august"
在map中写入数据时,内部的执行流程为:
第一步:结合哈希因子和键name生成哈希值
第二步:获取哈希值的后B位,并根据后B位的值来决定将此键值对存放到哪个桶中(bmap)。
``` 将哈希值和桶掩码(B个位1的二进制)进行&运算,最终得到哈希值的后B位的值。 假设当B为1时,其结果为0: 哈希值:011011100011111110111011010 桶掩码:000000000000000000000000001 结果: 000000000000000000000000000 = 0
通过示例可以发现,找桶的原则实际上是根据后B位的位运算计算出索引位置,然后再去buckets数组中根据索引找到目标桶(bmap) ```
第三步:在上一步确定桶之后,接下来就在桶中写入数据。
``` 获取哈希值的tophash(哈希值的‘高8位’),将tophash、key、value分别写入到桶中的三个数组中。 如果桶已满,则通过overflow找到溢出桶,并在溢出桶中继续写入。
以后在桶中查找数据时,会基于tophash来找(tophash相同则再去比较key) ```
第四步:hmap的个数count++(map中的元素个数+1)
value := info["name"]
在map中读取数据时,内部的执行流程为:
第一步:结合哈希因子和键name生成哈希值。
第二步:获取哈希值的后B位,并根据后B位的值来决定将此键值对存放到哪个桶中(bmap)
第三步:确定桶后,再根据key的哈希值计算出tophash(高8位),根据tophash和key去桶中查找数据。 当前桶如果没找到,则根据overflow再去溢出桶中找,均未找到则表示key不存在。
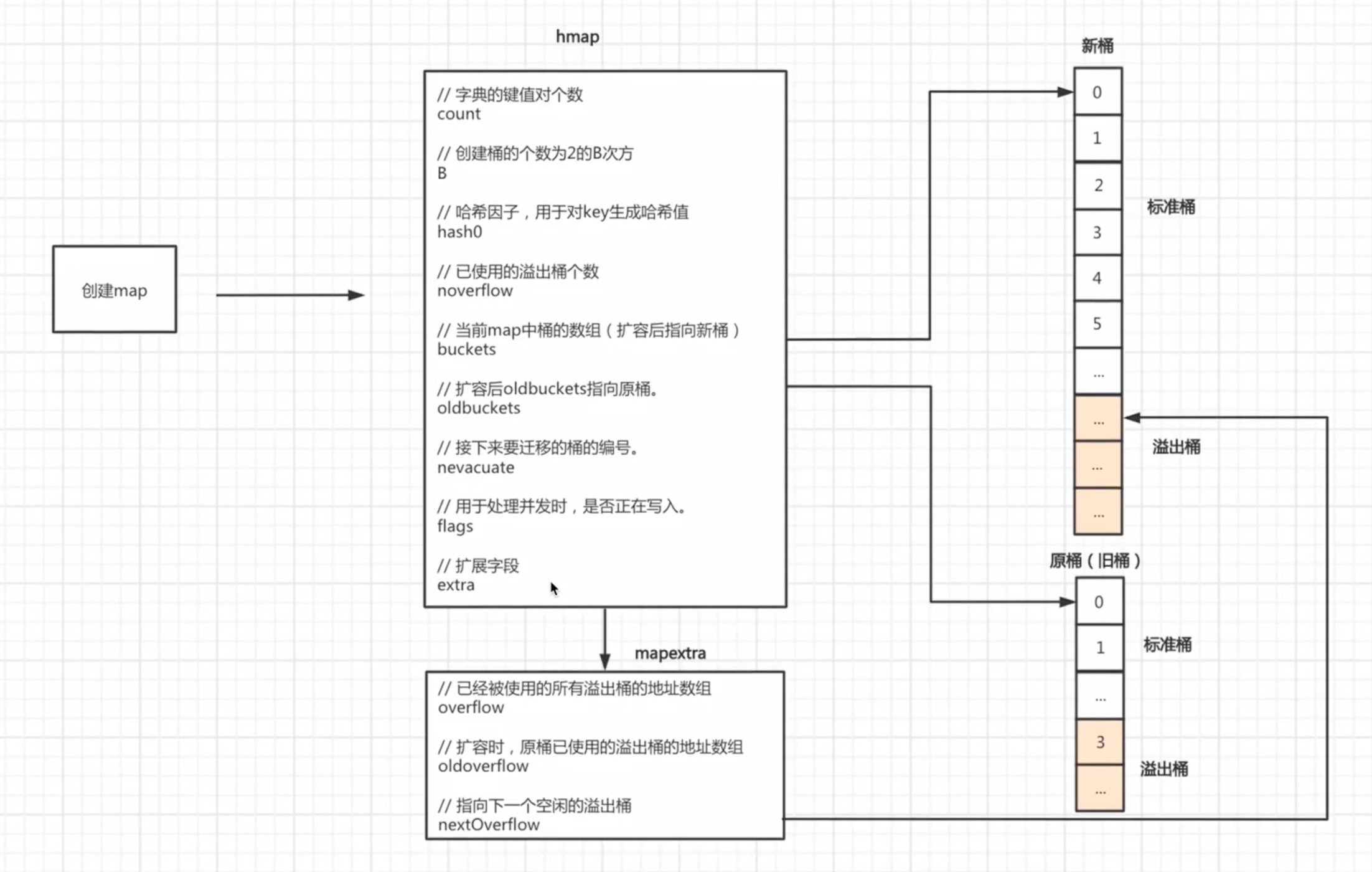
在向map中添加数据时,当达到某个条件,则会引发字典扩容。
扩容条件:
map中数据总个数/桶个数>6.5,引发翻倍扩容。
使用了太多的溢出桶时(溢出桶使用的太多会导致map处理速度降低)。
等量扩容。B>15,已使用的溢出桶个数>=2^15^时,引发等量扩容。
当扩容之后:
第一步:B会根据扩容后新桶的个数进行增加。
第二步:oldbuckets指向原来的桶(旧桶)
第三步:buckets指向新创建的桶(新桶中暂时还没有数据)
第四步:nevacuate设置为0,表示如果数据迁移的话,应该从原桶(旧桶)中的第0个位置开始迁移
第五步:noverflow设置为0,扩容后新桶中已使用的溢出桶为0.
第六步:extra.oldoverflow设置为原桶(旧桶)已使用的所有溢出桶。即h.extra.oldoverfow = hwxtra.overflow
第七步:extra.overflow设置为nil,因为新桶中还未使用溢出桶。
第八步:extra.nextOverflow设置为新创建的桶中的第一个溢出桶的位置。



基于Nginx+Supervisord+uWSGI+Django1.11.1+Python3.6.5构建