查询集,也称查询结果集、Queryset,表示从数据库中获取的对象集合。
在Model层中,Django通过给Model增加一个objects属性来提供数据操作的接口。比如,想要查询所有文章的数据,可以这么写:Post.objects.all(),这样就能拿到Queryset对象。这个对象中包含了我们需要的数据,当我们用到它时,它回去DB中获取数据。
当调用如下过滤器方法时,Django就会返回查询集(而不是简单的列表):
all(): 返回所有数据。
filter(): 返回满足条件的数据。
exclude(): 返回满足条件之外的数据。
order_by(): 对结果进行排序。
Queryset同时支持链式调用如:
posts =Post.objects.filter(status=1)
.filter(categroy_id=2)
.filter(ttile__icontains="django")
其在每个函数(或者方法)的执行结果上可以继续调用同样的方法,因为每个函数的返回值都是它自己,也就是Queryset。
链式调用这是一种更加自然的对数据进行处理的方式。数据就像是水流,而方法就是管道,把不同的管道连接起来形成“链”,然后让数据通过。
从SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by字句。
Queryset两大特性分别是惰性执行和缓存
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用。
例如,当执行如下语句时,并为进行数据库查询,只是创建了一个查询集qs
qs = Post.object.all()
继续执行遍历迭代操作后,才真正的进行了数据库的查询
for post in qs:
print(post.title)
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
如果是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from booktest.models import BookInfo
[book.id for book in BookInfo.objects.all()]
[book.id for book in BookInfo.objects.all()]
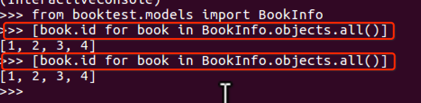
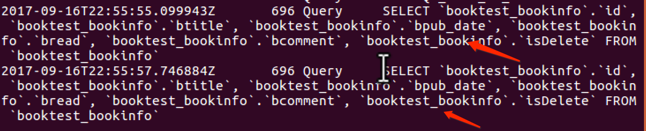
经过存储后,可以重用查询集,第二次使用缓存中的数据。
qs = BookInfo.objects.all()
[book.id for book in qs]
[book.id for book in qs]


可以对查询集进行取下标或切片操作,等同于SQL中的limit和offset子句。但不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]会引发IndexError异常,[0:1].get()如果没有数据则会引发DoesNotExist异常。
支持链式调用的接口即返回Queryset的接口,具体如下:
all(): 相当于SELECT * FROM table_name语句,用于查询所有数据。
filter(): 根据条件过滤数据,常用的条件基本上是字段等于、不等于、大于、小于、包含等等
exclude(): 同filter,只是逻辑相反。
reverse():把queryset中的结果倒序排列。
distinct(): 用来进行去重查询,产生SELECT DISTINCT这样的SQL查询。
none(): 返回空的queryset。
不支持链式调用的接口即返回值不是Queryset的接口,具体如下:
get(): 返回与给定的查找参数相匹配的对象。如果不存在,则爬出DoesNotExist异常。
create(): 用来直接创建一个Model对象
get_or_create():根据条件查找,如果没查找到,就调用create创建。
update_or_create(): 同get_or_create,只是用来做更新操作。
count(): 用于返回Queryset有多少条记录,相当于SELECT COUNT(*) FROM table_name。
latest()::用于返回最新的一条记录,但是需要在Model的Meta中定义:get_latest_by = <用来排序的字段>。
earliest(): 同上,返回最早的一条记录。
first(): 从当前Queryset记录中获取第一条。
last(): 同上,获取最后一条。
exists(): 返回True或者False,在数据库层面执行SELECT (1) AS "a" FROM table_name LIMIT 1的查询,如果只是需要判断Queryset是否有数据,用这个接口是最合适的方式。不要用count或者len(queryset)这样的操作来判断是否存在。相反,如果可以预期接下来会用到Queryset中的数据,可以考虑使用len(queryset)的方式来做判断,这样可以减少一次DB查询请求。
in_bulk(): 批量查询,接收两个参数字段值列表(id_list)和这些值的(field_name),并返回一个字典,将每个值映射到一个具有给定字段值的对象实例。如果没有提供id_list,则返回查询集中的所有对象。field_name必须是一个唯一的字段,它默认为主键。如果你传递in_bulk()一个空列表,将返回一个空字典。
values(): 当我们明确知道只需要返回某个字段的值,不需要Model实例时,可以使用它
values_list(): 同values,但是直接返回的是包含tuple的Queryset。如果只是一个字段的话,可以通过增加flat=True参数,便于我们后续处理。
还有其他用来提高性能的接口,在优化Django项目时,尤其要考虑这几种接口的用法。
defer():把不需要展示的字段做延迟加载。例如,需要获取到文章中除正文外的其他字段,就可以通过posts = Post.objects.all().defer('content'),这样拿到的记录中就不会包含content部分。但是当我们需要用这个字段时,在使用时回去加载。
only():同defer,刚好相反。如果只想获取到所有的title记录,就可以使用only,只获取title的内容,其他值在获取时会产生额外的查询。
select_related(): 返回一个Queryset,它将“跟随”外键关系,在执行查询时选择额外的相关对象数据。这是一个性能提升器吗,它导致一个更复杂的单一查询,但意味着以后使用外键关系将不需要数据库查询。用于解决N+1查询。
prefetch_related(): 返回一个Queryset,它将在一个批次中自动检索每个指定查询的相关对象。针对多对多关系的数据,可以通过这个接口来避免N+1查询。
contains: 包含,用来进行相似查询。
icontains: 同contains,只是忽略大小写。
exact:精确匹配。等同于=
iexact: 同exact,忽略大小写。
in: 指定某个集合,相当于Post.objects.filter(id__in=[1, 2, 3])相当于SELECT * FROM blog_post WHERE IN (1, 2, 3);。
gt: 大于某个值。
gte: 大于等于某个值
lt: 小于某个值
lte: 小于等于某个值
startswitch: 以某个字符串开头,与contains类似;只是会产生LIKE '<关键词>%'这样的SQL。
istartswith: 同startswith,忽略大小写。
endswith: 以某个字符串结尾。
iendswith: 同endswith,忽略大小写。
range: 范围查询,多用于时间范围,如Post.objects.filter(created_time__range=('2020-01-01', '2021-01-01'))会产生这样的查询:SELECT ... WHERE created_time BETWEEN '2020-01-01' AND '2021-01-01'; 。



基于Nginx+Supervisord+uWSGI+Django1.11.1+Python3.6.5构建