来看一张简单易懂的图理解一下python的引用语义和C语言值语义在内存中的存储情况,左右两个图,分别表示了python中变量存储与C语言中变量存储区别:
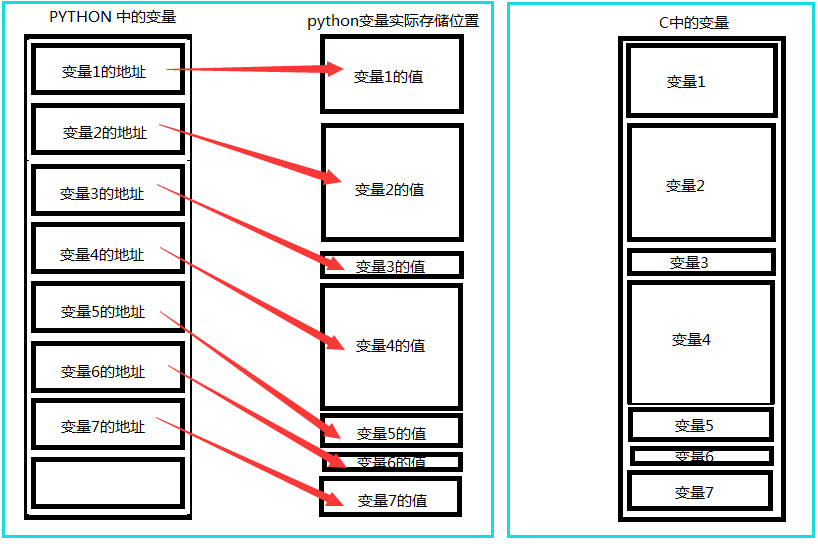
在Python中,对象的赋值就是简单的对象引用。如下所示
a = [1,2,"hello", ['python', 'Golang']]
b = a
# True
print(id(a))
# 140524502784992
print(id(b))
# 140524502784992
在上述情况下,a和b是一样的,他们指向同一片内存,b不过是a的别名,是引用。
可以使用b is a去判断,返回True,表明他们地址相同,内容相同,也可以使用id()函数来查看两个列表的地址是否相同。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是说除了b这个名字之外,没有其他的内存开销。修改了a,也就影响了b,同理,修改了b,也就影响了a。
简单的比喻一下,我们出去吃饭,a和b就像是同桌吃饭的两个人(赋值操作),两个人公用一张桌子(共享同一个内存地址),只要桌子不变(内存地址不变),桌子上的菜发生了变化两个人是共同感受的。
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。
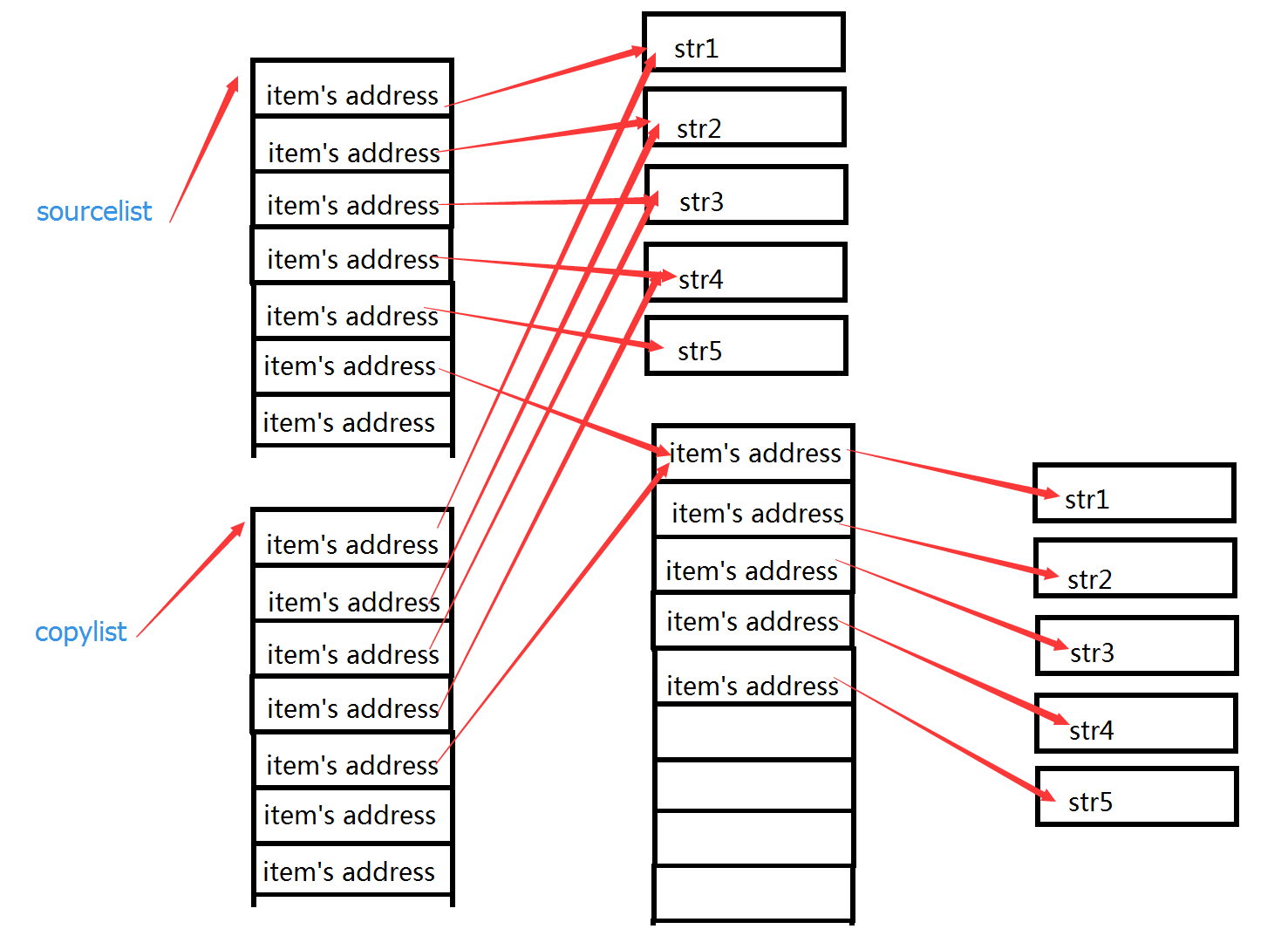 浅拷贝有三种创建形式:
浅拷贝有三种创建形式:
切片操作;
工厂函数;
copy模块中的copy函数。
例如:
# 比如上述的列表a;
# 切片操作:
b = a[:]
# OR
b = [x for x in a]
# 工厂函数
b = list(a)
# copy函数
b = copy.copy(a)
浅拷贝产生的列表b不再是列表a了,使用is判断可以发现他们不是同一个对象,使用id查看,他们也不指向同一片内存空间。但是当使用id(x) for x in a和id(x) fro x in b来查看a和b中元素的地址时,可以看到二者包含的元素的地址是相同的。
在这种情况下,列表a和b是不同的对象,修改列表b理论上不会影响到列表a。
但是要注意的是,浅拷贝之所以称之为浅拷贝,是它仅仅只拷贝了一层,在列表a中有一个嵌套的list,如果我们修改了它,情况就不一样了。
比如:a[3].append('java')。查看列表b,会发现列表b也发生了变化,这是因为,我们修改了嵌套的list,修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并未发送变化,指向的都是同一个位置。
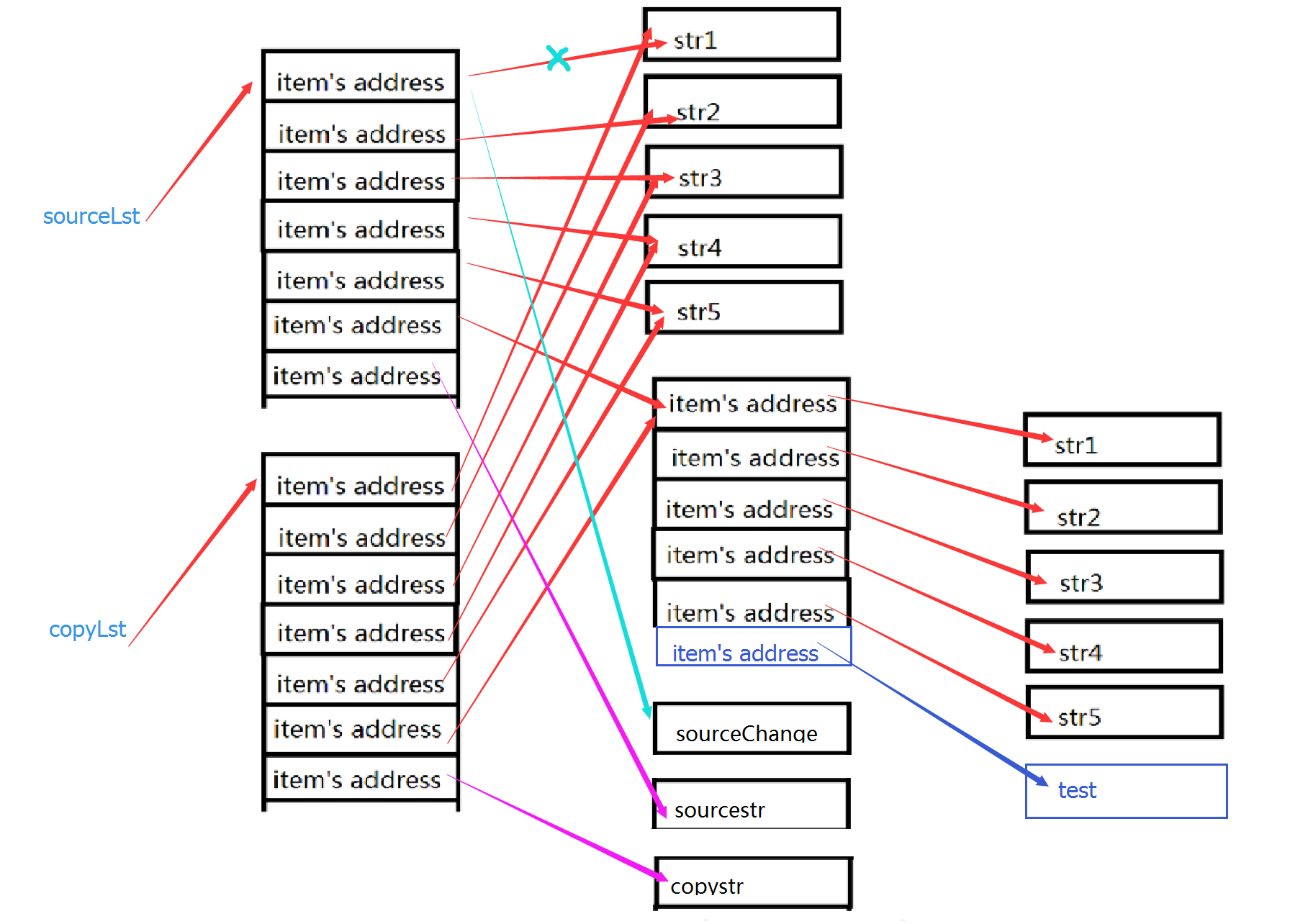
这种情况发生在字典套字典、列表套字典、字典套列表、列表套列表,以及各种复杂数据结构的嵌套中,所有当数据类型很复杂的时候,用copy去进行浅拷贝就要非常小心!
深拷贝只有一种形式,copy模块中的deepcopy()函数。
深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空间开销要高。
同样的对列表a,如果使用b = copy.deepcopy(a),再修改列表b将不会影响到列表a,即使嵌套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象,不再与原来的对象有任何的关联。
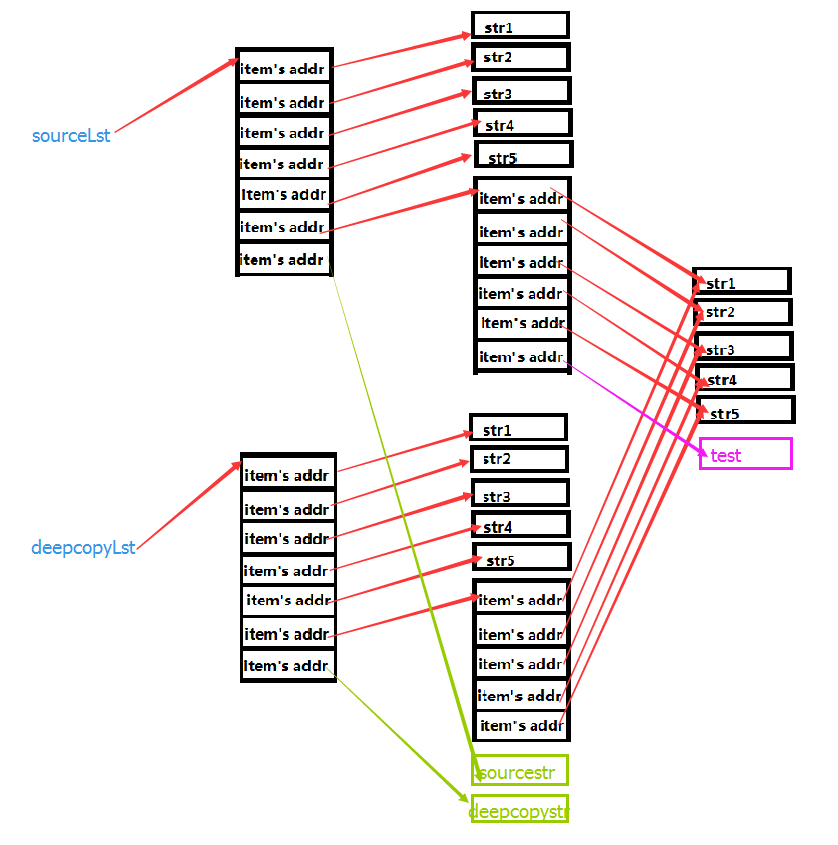
对于非容器类型,如数字、字符,以及其他的“原子”类型,没有拷贝一说,产生的都是原对象的引用。
如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝。



基于Nginx+Supervisord+uWSGI+Django1.11.1+Python3.6.5构建